Cluster F****: Part Two
Our initial, Cluster F*** post wasn’t written with a sequel in mind but today’s example presented itself and thus a sequel was born.
The most important part of the prior post and of this one as well is that the variables chosen to create these statistical clusters are all-important in creating (or avoiding) the garbage in/garbage out phenomenon.
Here is today’s real-life example. All of this is publicly available, including the underlying, raw data. This analysis was done by a large consultancy with a lot of foundation money supporting it. The work is highly competent and there is no issue with the statistical rigor. It probably cost about a bazillion dollars but reeks of quality so maybe worth the spend.
The goal is to create actionable clusters/segments based on responses to a detailed questionnaire. Ask a donor these 10 questions and the accompanying Excel tool will automatically score and place that donor into one of five segments based on the clustering algorithm. The answers to the questions represent the base variables or what is used to produce the clusters intended to create distinct segments with presumably different needs. Everything after that –including profiling the heck of out the segments with other data– is merely window dressing and probably more noise than signal – i.e. random and not helpful even though it makes for a pretty PowerPoint slide. And let me tell you, there are reams and reams of PP slides that go with this.
Ask yourself as a fundraiser: what value comes from knowing the answers to these questions? In the end you’ve taken data about a person’s attitudes on giving in general, how they got where they are in life, their generic satisfaction with giving, their generic future intent and, then, created generic segments.
The generic donor is now transformed into five generic profiles.

I’m repeating the term “generic” to underscore the fact that this methodology says absolutely nothing about why these donors give to your charity.
Here are the segments. Again, my answers to the 10 questions are what determine which segment I’m in. Anything of interest here?

A practical question: how does one find these people even if there were value in generic donor segments based on general sentiments about giving?
Fortunately, this research group also did real, in-market testing showcasing how to apply these findings for a generate lift. I was super intrigued…
They partnered with a charity in the health space to prove this out.
Step One: They hypothesized that the “Busy Idealist” was a good fit and that the best way for this charity to market to this group would be to highlight the ‘systemic change’ done by the charity. In the write up they cite that giving plays an important role to the Busy Idealist and that this person gives and volunteers a lot and tends to do more research and be a promoter of effective nonprofits to their peers. Nothing about that description seems to have anything to do with ‘systemic change’ but OK, I was still intrigued.
 Step Two: Next, they picked Facebook affinity groups interested in women’s right and poverty. Again, nothing to suggest that the “Busy Idealist” is disproportionately interested in women’s rights or poverty but I suppose one could argue this persona/segment exists within those populations. Great, let’s aim it at issues the charity focuses on and then tailor that messaging to match this Busy Idealist who “lives” among a larger population –those with women’s rights and poverty affinities.
Step Two: Next, they picked Facebook affinity groups interested in women’s right and poverty. Again, nothing to suggest that the “Busy Idealist” is disproportionately interested in women’s rights or poverty but I suppose one could argue this persona/segment exists within those populations. Great, let’s aim it at issues the charity focuses on and then tailor that messaging to match this Busy Idealist who “lives” among a larger population –those with women’s rights and poverty affinities.
Step three: Next, run an A/B test.
Control ad on the left. Test on the right. The test generated more likes and clicks that the control. It won.
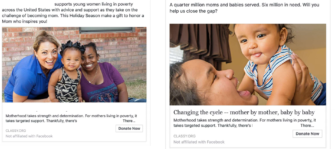
Step four: Analyze and prove out the segmentation. This proves something; if you aim a message at an audience and focus most of the message on who the audience is and less on the organization you can do better than a generic, organization centric ad.
The problem for this consultancy and the resulting segmentation that cost a bazillion dollars and makes for lovely slide decks and a slick typing tool in Excel?
- I didn’t need Step One….
- …because I didn’t need the study or the segments from it.
That part is completely irrelevant to the success of this ad. There is nothing about the ad that is tied to the theoretical, cluster-derived segment. And in trying to ‘shoe-horn’ it into the “strategic thinking”, it only obfuscates and muddies the water of Identity based marketing, which has reams of theoretical and applied evidence behind it.
But, if all you’ve got is a hammer (their bazillion dollar study), everything is a nail.
The lesson in all of this is not to ignore research and go straight to live testing. All live testing should have some theoretical or evidence base to support putting real dollars at risk, if only for the opportunity cost of those dollars.
Sadly, most testing is random and not evidence based. This work starts with a huge evidence base but fails to connect that to any meaningful application.
Both are sins. You can decide which is bigger.
Kevin
Behavioral Science Q & A
Integrating an individual giving appeal with other communications from a charity can have both positive and negative effects, and the outcome largely depends on how it’s executed. Advantages of Integration Brand Consistency: Maintaining a consistent appearance and messaging across all communications can reinforce the org’s brand identity and strengthen brand recognition and trust among your […]
Read Full Answer
I’m not aware of any in-market tests specifically comparing recurring vs. gift frequency language. I suspect the answer might not be the same with all gift frequencies, nor with all people. It sounds like a great opportunity for you to test and find out what works for your audience. Based on the literature, here’s a couple […]
Read Full Answer
Based on what we know from existing data, those renewal notices can actually be pretty effective in getting people to donate. They tap into our psychology – creating a sense of urgency, reminding us of past support, and using personalization to make the message hit home. They’re playing on our natural tendencies to feel obligated […]
Read Full Answer
Interesting question. I had a quick look at the testing done on this topic. On the positive side, in all cases, over half of donors decide to cover the fee. In some cases, it goes as high as 65%. Not a negligible percentage at all. Here’s another test from iRaiser showing consistent results (see point […]
Read Full Answer
There’s just one thing to consider when designing a supporter journey: the supporter. More specifically, you need to take into account: Who the supporter is i.e. their identity, which is the reason they support this cause, and their personality, which describes the way they “see” and process the world. These will determine the kind of […]
Read Full Answer
I’m not an expert in this but a quick search surfaced this article on the effect of tax reforms on 2019’s charitable giving. The researchers didn’t find a reduction. Actually, they observed an “increase in charitable contributions in 2019, even with the lower tax rates and the dramatically smaller number of taxpayers who itemize their […]
Read Full Answer