Human vs. Machine
We humans built the machines so the “vs.” doesn’t properly credit our maker status bona fides. Having said that, machine is often much faster and yes, better.
Here’s another instance that feels pretty close to home. This experiment used professional copywriters to draft ad campaign copy, 100 words or fewer, for an NGO for four different scenarios – social justice, environmental protection, obesity, disease prevention, climate action.
There were four copywriting conditions,
- Human Only
- AI Only (GPT was used)
- Human first draft, AI final draft
- AI first draft, Human final draft
The results didn’t differ across the issue scenarios and so results are presented in consolidated form for simplicity. The satisfaction ratings were provided by a sample of prospective donors who also rated the various copy treatments on other dimensions (e.g. persuasiveness, willingness to donate) and again, the patterns were the same so sharing satisfaction ratings only.
The final condition is the degree of information explicitly shared about AI involvement in the copywriting process.
- Baseline: The blue bars where nothing was explicitly mentioned to the raters about AI. The AI-only copy is the clear winner.
- Orange: These raters were told that AI was used in the creation of at least some of the copy but not told which version. AI being the only or final writer wins.
- Gray: These raters knew which version was produced by AI, human or both and how. Again, AI being the only or final writer wins.
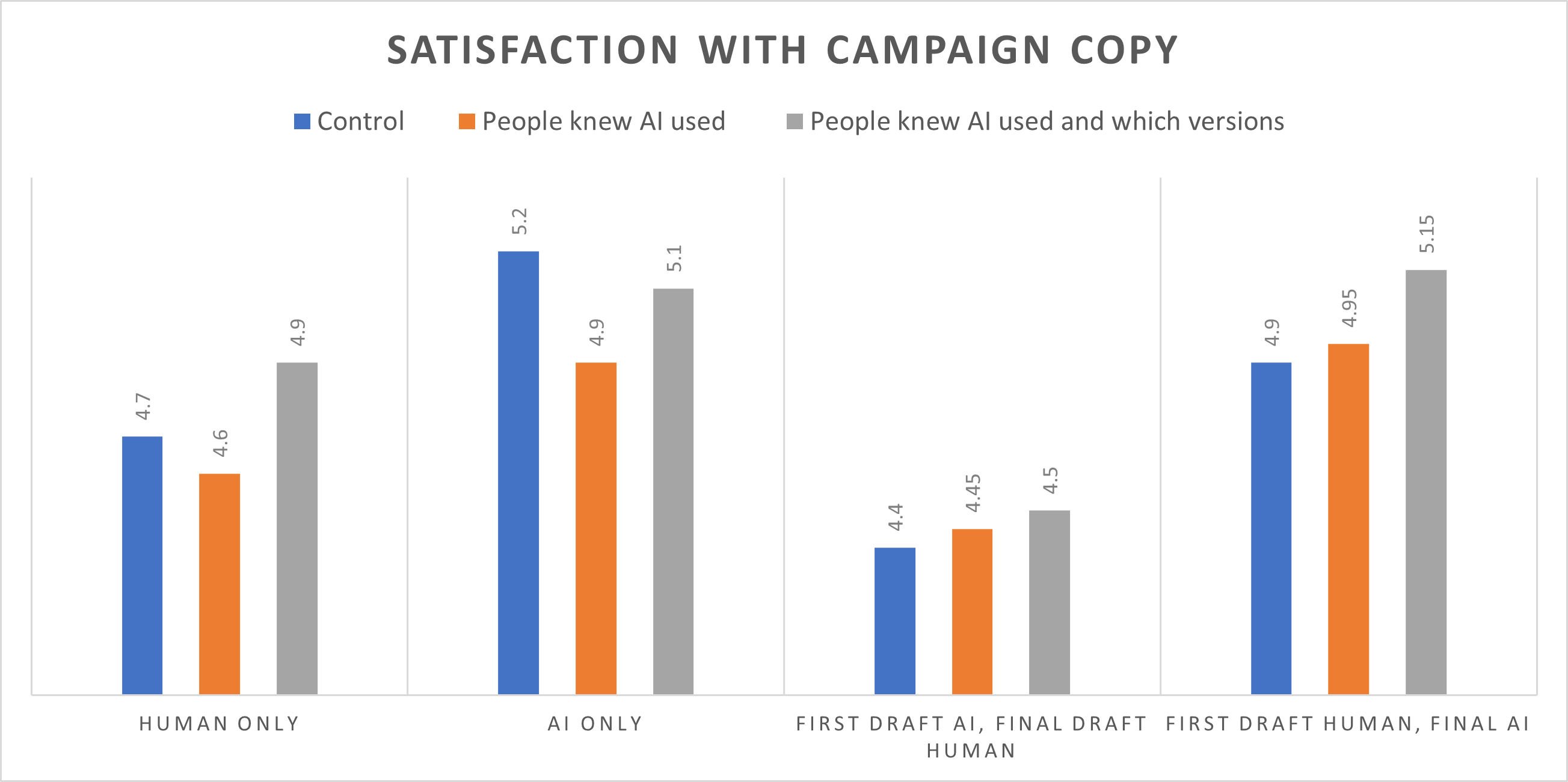
The least good approach across all conditions is humans working off a first draft produced by AI. It’s much better the other way around. What isn’t reflected here is our approach, which is a bit of a Human-AI-Human Oreo. We feed it lots of generalized guidance as standing instruction plus specific examples, get its draft and lightly edit it.
The bottom-line takeaway? These are professional writers. At minimum, AI will make you faster and more productive. With some trial and error, it has the potential to make you better too.
And since this isn’t Lake Wobegon a lot of copy is below average. DonorVoice research scoring hundreds of fundraising samples on Readability and Story with our Copy Optimizer tool suggests the sector corpus isn’t a bell curve, the crappy pile of copy is much larger than the good one.
This means a lot of organizations paying someone to write copy or having someone do it off the side of their desk would be better off using AI only.
Kevin
7 responses to “Human vs. Machine”
Behavioral Science Q & A
Whether “help” is more engaging or not really depends on the framing and context. The word help can sometimes weaken the perceived agency of the supporter, making their role feel secondary rather than central (your point). On the other hand, help can also signal collaboration rather than implying full ownership of the outcome, which might […]
Read Full Answer
Great question! Here’s how behavioral science can help unpack what might be happening: Pain of Paying: Even a small extra charge can make giving feel more transactional than emotional, potentially reducing generosity. Fairness Concerns: Some donors might perceive donor cover as a surcharge rather than a contribution to the cause. If they feel the charity […]
Read Full Answer
The choice between “Your gift CAN…” and “Your gift WILL…” taps into the psychological framing of certainty vs. possibility. Currently, there is no academic research directly comparing these two framings in charitable appeals. However, I suspect no framing is universally better—the outcome likely depends on your target audience and the campaign’s goal. Here are some thoughts: Certainty Framing – […]
Read Full Answer
Integrating an individual giving appeal with other communications from a charity can have both positive and negative effects, and the outcome largely depends on how it’s executed. Advantages of Integration Brand Consistency: Maintaining a consistent appearance and messaging across all communications can reinforce the org’s brand identity and strengthen brand recognition and trust among your […]
Read Full Answer
I’m not aware of any in-market tests specifically comparing recurring vs. gift frequency language. I suspect the answer might not be the same with all gift frequencies, nor with all people. It sounds like a great opportunity for you to test and find out what works for your audience. Based on the literature, here’s a couple […]
Read Full Answer
Based on what we know from existing data, those renewal notices can actually be pretty effective in getting people to donate. They tap into our psychology – creating a sense of urgency, reminding us of past support, and using personalization to make the message hit home. They’re playing on our natural tendencies to feel obligated […]
Read Full Answer
Hi Kevin, I’d be interested in knowing the prompts that were fed into the AI model.
What prompt was used to tell AI to rewrite the copy – according to “copywriting best practices?” or “Fundraising best practices?” etc?
Thanks, Gail Perry
Hi Gail, the instruction given to AI was to write persuasive, compelling copy, max 150 words, for an upcoming campaign on [Issue X] for an NGO. And then the human version was simply cut and paste as an example, no additional prompting.
I agree that AI can be used as an effective tool by professional writers. Because they know what good copy looks like. A professional copywriter will keep prompting and refining. An untrained copywriter will settle for anything that sounds “fundraisery”. Your outcomes were the results of AI being used by professional copywriters, correct? In most people’s hands AI will just make terrible/mediocre faster and easier.
But I’m puzzled by your experiment… you’ve ask donors for their OPINION of copy? Am I understanding this correctly?
Why not an actual split test? It’s been proven over and over, what donors say when asked their opinion and what they actually respond to, are very different.
What donors say they prefer does not match what they actually do when responding in real life. Anyone responsible for producing actual results in direct response knows this.
What we don’t know from this experiment is if ANY of this copy performed well. Actual, real-world results are what we judge fundraising copywriting by… not opinion.
On the upside. AI will be most useful in digital since it can be tested and refined very quickly to produce the best results.
My prediction is that our human brains will subconsciously learn to recognize and ignore mediocre AI copy just like our brains are highly trained to subconsciously recognize and ignore markety-marketing. The human and the authentic will continue to outperform everything else. The ocean of mediocrity will grow exponentially with AI. Unique, authentic and human communication will stand out even more.
Denisa,
Yes, it was professional copywriters and these results suggest that AI only is better than any option that includes those professional copywriters using AI, especially with the professional human being the final editor. To extend this, it’s reasonable to hypothesize that AI only is also the best option for a non-professional writer. We aren’t turning everything over to AI at our agency, instead relying on the Human-AI-Human Oreo but maybe that’s our own hubris… It’s true the way this copy was evaluated by ratings but those ratings and any bias is equally applied so the relative winners/losers findings still have value.
I’ll concede that most research is garbage with poorly constructed questionnaires and elementary analysis that ignores the complexity of humanity. There are however, ways to conduct research that provide insight into motivation and preferences that matches the real world quite well. But why bother? Why not just do all in-market testing?
I’ll offer up 2 reasons:
1) Attitudes and beliefs and preferences and yes, opinions matter if one is trying to infleunce behavior. All of these ‘mind’ metrics are the antecedents to many/most in-market choices. Understanding these drivers of behavior gives me strategic guidance for all the expensive, time consuming in-market work. It increases the chance of success. I say this not just as a researcher but as someone running an agency that is responsible for producing results.
2) There are research methodologies that let me pre-test thousands of ideas in the span of 2-3 weeks in a research environment that is inexpensive, risk-free and saves enormous time and money to find the needles in the haystack worth putting in-market
And it’s worth noting that in-market testing shouldn’t always be held out as a gold-standard. From what I see, most in-market testing is poorly conceived, poorly executed and poorly analyzed and almost always, forcing a one-size fits all mindset to a heterogenous world. The random nth selection method for splitting test and control is case in point. And as we noted in recent posts, short-term results don’t always match long-term, often they are the opposite.
If you’ve done decades of high-performing campaigns AND asked donors which ones they prefer… you very quickly find out that what they say they prefer, and what they actually respond to in the wild, are very different. (same with Boards and their opinions)
Your blog could easily be very misleading to anyone in a normal charity(90% of US orgs). They are not and probably never will, use modelling on their small/med size donor base.
So many of the tools used by charities with massive donor bases do not work very well for 90% of charities. There’s a few very simple reasons:
A) Producing a .2%(2/10 %) increase in RR’s, in a database of millions, will effect the bottom line and be considered a win. In a database of 3-10K it makes very little difference and probably doesn’t justify the resources spent testing. In a database of 15K a +.2% variance is considered background noise and in no way marks a DM Appeal as more successful. But at a large charity it’s a win.
B) Charities with massive donor bases work on small margins. Just like other big companies that mass market. They don’t have to produce more than 3-4% RR’s for DM campaigns to be viable. But a small/med charity really needs RR’s more like 8-12% RR’s to be viable.
C) Local charities can’t use digital in the same way regional/national/international charities can. Their universe of possible donors is very small and most digital strategies rely on low % RR’s from a very large digital audience.
I’ve worked with both large & small and now focus on sm/md orgs because they are vital to so many communities and have to produce a lot more with less resources. My biggest problem with many of your posts is their relevance to 90% of charities… and the lack of context(or lack of understanding) around how different the top 5% function from the rest of us.
For context… I have a Behav. Sci. degree and have had the privilege of working with a team that included a PHd doing our modelling. It was absolutely fascinating and it produced incremental gains in big data sets.
But I have NEVER seen gains like we see when we work with top creatives in the sector. We saw an international charity go from 22% RR to 33% RR from one Christmas to the next. Because we brought on one of the top copywriters in the world. That’s right. A 50% increase in RR’s (across 6 countries). This was 30K donors… so not a small charity. But we regularly see double digit increases in RR’s when we bring in top creatives.
So do I think your modelling is going to improve copywriting… no, I remain unconvinced. But I do think it’s a useful tool, in the right circumstances when combined with good quality creative.
I agree with Denisa. The only useful measurement would have been what donors DO, not what they say. They don’t have to like or dislike the copy… but we want them to act on it.
Hi Mary, hope 2024 is off to a good start and thanks for commenting. I’ll note again that the measures were done the same way across all the treatments so whatever bias you think might exist in a stated preference, it is a constant in this equation, meaning the relative winning and losing copy findings still hold. I’d also reinforce the counterpoint, which is that people’s attitudes, beliefs and opinions are manifestations of their motivations. And their motivation is what causes the in-market behavior we all rely on to judge success or failure.
If you show me four copy snippets and I tell you I like one of them much better than the other 3 and you repeat this exercise for 1000 people and find a clear preference for one of the four I wouldn’t ignore that or consider it irrelevant or assume it’s the opposite of what I really like. Now asking people why they like something is tricky and often leads to artificial and misleading answers.
A case in point, we use a research methodology to gauge preference (not asking why) on thousands of treatments. We did this for Heifer and it led to them finally beating the control mail catalog for the first time in 15 plus years and after hundreds of in-market, direct mail tests that failed to beat the control. We told them what the in-market testing couldn’t.