The Model That Knows When To Shut Up
Most fundraising models rely on a simple set of assumptions:
-
Recency means readiness
-
Frequency means loyalty
-
Bigger gifts mean bigger love
And that all this adds up to a reliable way to pick who gets your next fundraising appeal. But here’s what most models don’t ask: What happens when you actually market to someone? Did they give because of that last email — or despite it?
The modeling every organization needs doesn’t just track donation behavior, it tracks what donors received so it can learn which donors respond to heavier contact, which prefer light touches, and which ones quietly stop giving when the volume gets turned up.
And crucially, it predicts how likely someone is to give in a particular month, based on when and how they’ve been contacted in the past.
That makes possible something most models can’t do: A donor-specific pulsing calendar. Here’s what that looks like in its simplified form with individual donors rolled up into groups for ease of visualization.
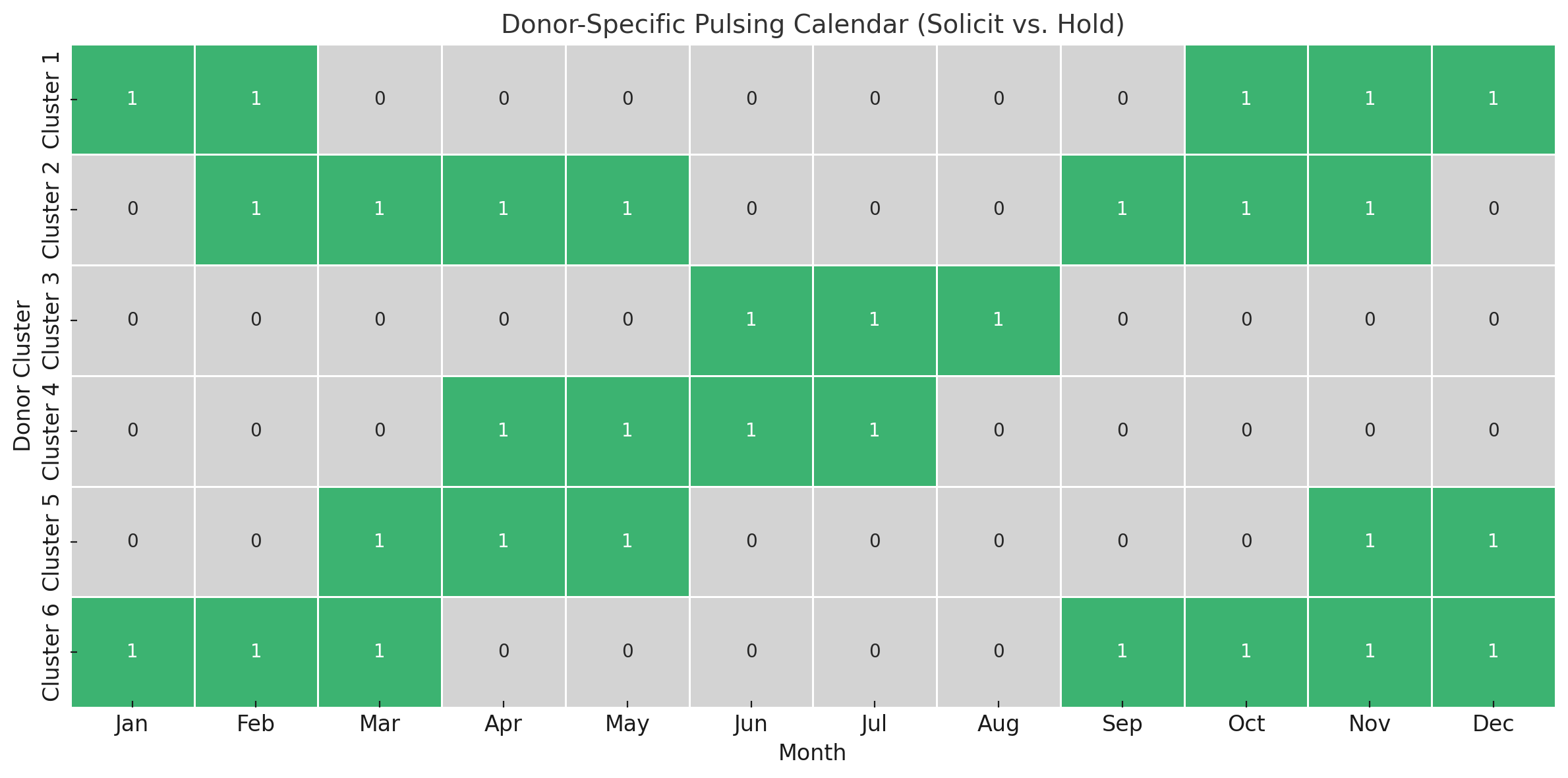
Green = solicit this month. Gray = hold off. Each row is a donor type with its own optimal cadence.
Some donors are classic year-end givers. Others are mid-year responders. Some give like clockwork once a year (but not all in December), these are anniversary donors, each with their own preferred giving month. Our model recognizes those patterns and builds a custom cadence around them.
This isn’t about who gave recently. It’s about who’s likely to give if we ask now — and who’s better off left alone.
Most “personalization” in fundraising is surface-level. Change the salutation. Swap the photo. Vary the copy block. But the cadence stays the same.
Real personalization means:
-
Knowing who responds to outreach
-
Knowing who gives after silence
-
Knowing who needs a nudge
-
And knowing who needs a break
That’s personalized pulsing — customizing the rhythm, not just the message. Is your agency doing this for you? Here’s your five-point gut check:
1. Does it include your marketing history — not just giving?
If the model only looks at who gave and when, and ignores how often you’ve asked, you’re modeling outcomes, not behavior.
2. Does it learn how each donor responds to being asked?
If it treats marketing as background noise or assumes everyone reacts the same way, you’re not capturing real-world dynamics.
3. Does it model irritation and memory?
If the model doesn’t learn that too much contact can backfire or that a well-timed appeal can have a delayed payoff it’s missing the behavioral nuance that drives real response.
4. Does it predict when not to ask?
A good model isn’t just about green-lighting solicitations, it should know when to pause to avoid burnout or tune-out.
5. Does it personalize cadence not just content?
Changing the message to match the person is mission critical. But if every donor is on the same calendar, you’re still treating them like a segment, not a person.
This approach, whether built internally or with a partner, respects your donors, saves you money, and gets better results. Because sometimes the smartest thing you can do isn’t ask more, it’s know when to shut up.
Kevin
4 responses to “The Model That Knows When To Shut Up”
Behavioral Science Q & A
Thanks so much for raising this. Yes, capturing donor information can be helpful for stewardship like newsletters, thank-you letters, impact updates. But how you ask matters. Forcing full data capture introduces friction that can significantly depress conversion, many donors may simply abandon the process. Beyond the friction itself, required fields also shift the emotional experience […]
Read Full Answer
Unlike holidays that everyone already knows, Giving Tuesday is a created event. Many donors recognize the name but not the exact timing, so referencing it becomes a helpful cue. It serves as a reminder and taps into social norm activation (“everyone’s giving today”), which boosts response. However, we still want it paired with the mission, […]
Read Full Answer
When a subject line leads with the match (“Your gift matched!”), it risks triggering market-norm thinking: the sense that giving is a financial transaction rather than an act rooted in values, identity, and care. This shift reduces intrinsic motivation and, over time, can weaken donor satisfaction and long-term engagement. It also makes the email indistinguishable […]
Read Full Answer
There’s no evidence that QR codes suppress mid-value giving; all available research suggests they either help or have no negative effect. In fact, behavioral and usability research consistently shows the opposite: reducing friction at any point in the donation process increases completion rates and total response. And that has nothing to do with capacity and […]
Read Full Answer
What you’re experiencing is very common. Resistance often isn’t about capability, but about motivation quality. If board members feel pushed into fundraising, that triggers controlled motivation (low quality motivation) i.e. obligation, guilt, or fear of judgment, which often results in avoidance. Instead, we need to create conditions for volitional motivation (high quality motivation) by satisfying […]
Read Full Answer
That’s a really thoughtful question, and you’re not the first to raise it. Many of our clients have been cautious about placing the ask at the very end. To address their concern, we’ve tested both approaches, and the results are clear: when the ask comes last, even if that means it appears on the second […]
Read Full Answer
THIS: does it include your marketing history — not just giving? AMEN!!!
Hi Lisa, yes, agreed – this is the key point and fatal flaw with 99% of models I’ve seen, including those from big agencies. They only use transaction data. This means, by definition, they are comparing Jack Donor to Jill Donor. It also means, by definition, that if Jill is a better donor than Jack on average, she’ll get selected for solicitation every time. And we will turn Jill into a “bad” donor as a consequence.
Why should we force Jill to make up for Jack’s donor deficiencies? I want to make decisions about Jill based only on her behavior in reaction to her promotion history – i.e. the behavior of the charity.
hi Kevin, in theory this all sounds great. Yes, most nonprofits’ databases do keep the donor’s giving history and appeal history (by channel) so that information is available. But sometimes that’s where it ends.
When you talk about a model, which model are you referring to and where is it available? There are so many modeling companies now that it would be helpful to be more specific. As far as I know, several companies are using both appeal history and giving history.
Also, I’ve seen this time and time again, what donors say and what they do are two very different things and the same apples to models.
So model with care and test and reverse test but most importantly, determine what you’re trying to test and why and determine what you want the model to do.
I’d be extremely curious about a model that can measure the donor’s irritation of getting yet another label package. How can you measure something like that just because the donor does not respond? Is there a camera built into the package? (yikes, scary)!
Also, determine what’s the goal of the model. Is it to save money by not mailing those who will never make another gift? Is it to raise more money?Is it to reactivate lapsed donors? Is it to find new prospects? Is it to find monthly donors within your donor base? I’ve seen hits and misses with models and always recommend testing a model versus your fundraisers gut and/or experience and see what happens. Models do cost money so make sure you use them where it makes the most sense.
There’s a lot here but let’s get past the generic platitudes.
This model is real, built by DonorVoice, and applied by us, every day, for our agency-of-record clients. It’s not a sales pitch however, this is only available from us for our AOR clients. It was written to note two things,
1) highlight how desperately the sector needs to replace what passes for modeling today. Because in most cases, it’s still just RFM with lipstick.
2) that this model is ‘stealable’, repeatable. There is nothing proprietary here, the only thing required is mindset shift and technical chops, latter can be rented, former is biggest barrier.
This model, using transaction and promotion history, accounts for concepts like adstock (positive memory) and irritation (negative response to overexposure). Those aren’t buzzwords. They’re functional parameters in a time-series framework. They’re not theoretical. They’re built to predict and change donor behavior, not simply describe it after the fact.
Irritation isn’t a vibe. It’s a measurable decay effect. When you see diminishing returns despite sustained or increased promotion, you’re watching irritation outpace positive memory associations. And when you don’t account for that, which almost no one does, you end up over-communicating, over-asking, and blaming the donor for “fatigue” when the fault lies entirely with the machine.
As for the “goal of the model,” I appreciate the list you rattled off but it misses the mark. This model is built with a singular purpose: to grow donor value by personalizing how and when to interact with an individual donor. It is the operational answer to the sector’s most important question: what’s the best way to interact with this person to retain them and grow their value?
Your point about “donors don’t do what they say” seems like a red herring in this context. This model doesn’t use survey data. But more broadly, that critique is as wrong as it is right. Dismissing donor-reported data outright ignores decades of rigorous academic work on validated scales, indirect measures, and behavioral diagnostics. There are many critical insights you can’t get from behavior alone – e.g., motivation, identity, satisfaction, emotional response. Not everything shows up in the transaction log. But again, that’s not what this model is using, so not sure of your intent in raising that point.
And finally, I’d suggest we stop romanticizing “gut” or “experience” as some noble counterbalance to data. It’s local optimization. It leads to overfitting strategy to the last bad test or best-performing label pack. And it’s a big part of why donor files are shrinking.