Does Your A/B (Testing) Need to Meet C and D?
What do 127,000 experiments over five years from a variety of sectors, including fundraising, tell us about what’s required to run better experiments? First, let’s define better:
- higher chance of winning and
- bigger uplift,
- which creates a multiplier for expected impact; the % chance of winning * likely uplift = expected impact.
Here’s our take on the 4-part key to better testing based on a great report from Optimizely.
-
-
- Getting beyond A/B tests to A/B/C/D etc. testing. More variants = better. Three-quarters of tests are A/B tests with an expected win rate of 10% and low lift. Going to 4 variations doubles the expected win rate and nearly doubles the expected lift, which more than triples expected impact. The reason for this isn’t just more, it’s more diverse and novel ideas. The test version in an A/B test is very likely to be low risk and design by committee with hierarchal decision making to boot (i.e. boss decides, ugghhh). More variants is an idea liberator.
- Aim higher in the funnel. Last mile testing is, by definition, on the smallest group of people. Impacting revenue per visitor is a low impact experiment as is average donation value. There is much greater impact with search rate on site and registration rate. Search rate, for instance, has an expected return almost 5x that of a revenue per visitor goal. Fish where all the fish are, which ain’t the last mile optimization.
- More complex changes. Harvard Business School ran a regression analysis to determine the test attributes influencing lift size. One of the biggest factors is the degree of coding changes for the test. Wonky but senseful. Changes to text, color, image, layout, # of fields etc. are all simple, low to no code change tests. Bigger coding changes have a bigger impact on user experience and allow for bigger, bolder test ideas. Small test = small, expected impact. Great experiments require trying large leaps in user experience because low hanging fruit dries up. There is an inter-related cultural piece here. To get bigger tests approved likely means more senior leaders getting involved and invested. Nobody needs to approve (or care about) a button color test.
- More personalization. Only about half of experiments are personalized by what is known about the user – e.g., new/returning, geolocation, source, internal segmentation. Those that personalize are 41% higher impact.
-
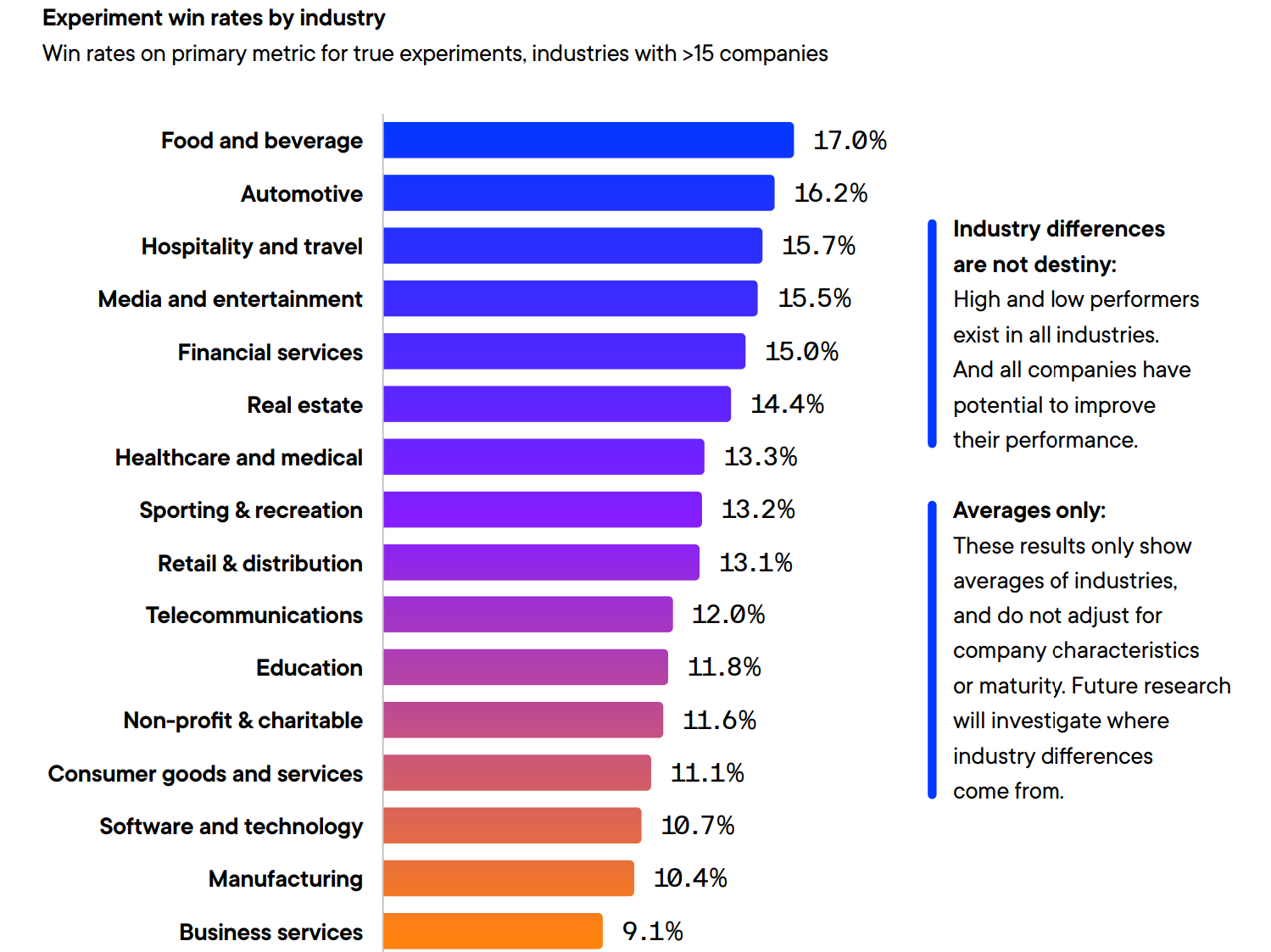
How does our sector stack up? Bottom third on win rates and remember, win rate is only half the equation that matters to impact. The other half, expected lift, is the Big 4 we just reviewed.
So how do you abide by the Big Four?
Testing more often isn’t enough and “winning” isn’t enough if your winning is A/B tests on low-end, no personalization ideas. You will always have a high failure rate, the question is how big your successes are. If small the failure can swamp out the upside.
The key from a testing guru at Amazon, “Pair complex tests with a theory. Theory and testing together can help firms unlock breakthrough performance”
Where can you get theory? Desk research, Ask a Behavioral Scientist, etc. Big wins are what matters, and it requires bigger, bolder thinking.
Kevin
Behavioral Science Q & A
Thanks so much for raising this. Yes, capturing donor information can be helpful for stewardship like newsletters, thank-you letters, impact updates. But how you ask matters. Forcing full data capture introduces friction that can significantly depress conversion, many donors may simply abandon the process. Beyond the friction itself, required fields also shift the emotional experience […]
Read Full Answer
Unlike holidays that everyone already knows, Giving Tuesday is a created event. Many donors recognize the name but not the exact timing, so referencing it becomes a helpful cue. It serves as a reminder and taps into social norm activation (“everyone’s giving today”), which boosts response. However, we still want it paired with the mission, […]
Read Full Answer
When a subject line leads with the match (“Your gift matched!”), it risks triggering market-norm thinking: the sense that giving is a financial transaction rather than an act rooted in values, identity, and care. This shift reduces intrinsic motivation and, over time, can weaken donor satisfaction and long-term engagement. It also makes the email indistinguishable […]
Read Full Answer
There’s no evidence that QR codes suppress mid-value giving; all available research suggests they either help or have no negative effect. In fact, behavioral and usability research consistently shows the opposite: reducing friction at any point in the donation process increases completion rates and total response. And that has nothing to do with capacity and […]
Read Full Answer
What you’re experiencing is very common. Resistance often isn’t about capability, but about motivation quality. If board members feel pushed into fundraising, that triggers controlled motivation (low quality motivation) i.e. obligation, guilt, or fear of judgment, which often results in avoidance. Instead, we need to create conditions for volitional motivation (high quality motivation) by satisfying […]
Read Full Answer
That’s a really thoughtful question, and you’re not the first to raise it. Many of our clients have been cautious about placing the ask at the very end. To address their concern, we’ve tested both approaches, and the results are clear: when the ask comes last, even if that means it appears on the second […]
Read Full Answer